
Introduction
TL;DR – this is a venture into application side of gBoxADTBase type implementation.
This post is a continuation of the series on Type-safe Entity Modeling of domain entities. The implementation design is based on Scala language constructs such as Case Classes, Annotations, Compile-time Macros, and the Reflection API. The library is named as gBoxCPCommons – set of base-line functions that are applied across various aspects of a conversational pipeline framework.
Objective here is to derive a tool agnostic approach to design and maintain entity compositions (representing domain objects). And, extend their behaviors i.e., traits in an implicit manner, often influenced by various contextual needs.
One such desire was to integrate the types with data processing frameworks such as Apache Spark, Flink, etc. The effort is also a part of experiment to come up with a conversational pipeline design-implementation. Conversational pipes are based on immediate feed-back loops, such that scale is achieved as a natural factor, rather a monitored activity.
Now to this post – the immediate challenges to achieve the desired integration with Spark were ability to attain and support binary compatibility with Scala versions. Some back-porting and trade-offs were necessary.
I believe given the time Spark as a framework existed and has evolved, it probably needs very little introduction. But for curious minds – let’s call it a distributed data processing framework, with support for a wide variety of data function support. Including querying, slicing/dicing and to the most interesting Machine Learning capabilities. At it’s core are two key facets – in-memory storage (of data that tasks would act upon) and the presence of Resilient Distributed Data (RDD) sets, that are processed in either a batch or micro-batch mode. To simplify adoption and enhance expressiveness the DSL (Domain Specific Language) provides wide-variety of interfaces such as DStreams, Dataframes, and Datasets.
Integration effort here focuses on incorporating the traits that were explored in my previous posts – Serialization and Deserialization, and see how they can be applied to data processing first-steps inside Spark. Goal here is to continue to ensure type-safety!
Accommodations
In order to achieve binary compatibility with Spark the gBoxCPCommons library required some breaking changes. Primarily to support the official Scala version supported by Spark i.e., Scala 2.11.x. The gBoxCPCommons is originally built on Scala 2.12.x. Few things that I needed to give away include Scala-to-Java closure auto-transformation, ability to leverage Symbol API from the Scala Reflection, and likes. Another critical piece is how type references are passed onto the serialized code instances.
Here’s the break-down detail of such refactored changes (actually created a forked out version of gBoxCPCommons for Scala 2.11.x):
- Serialization: First challenge is associated with TypeTag serialization. TypeTag references Type, which in turn references Symbols. Symbols cannot be serialized. Alternative choices indicated in the community is to make any symbol references transient. ClassTags, however do support serialization. These are widely used within the Spark code base.
- Kryo Registration: Reference implementation described in the use case below, takes care of registering the T<:gBoxADTBase[T], with Kryo serializer. Configuration applies KryoSerializer as the default serializer, along with appropriate Ser-De instance for the corresponding type.
- Scala to Java Closures & Cache Implementation: Implementation of the default cache – gBoxCPCommonsCacheImpl depends on lambda support for SAM (Single Abstract Method) types. This allows one to take Scala closures and pass them to the Java library that accepts Java functions (i.e., scalaFn.asJava sort of). This is not a supported feature in Scala 2.11.x. To work around this limitation, instead of depending on Caffeine library’s signature, a similar solution is derived using low latent locking mechanism. Leveraged the java.util.concurrent.locks.ReentrantLocks feature in Java. This enables concurrency with low-latent locks while the cache implementation applies the user defined value function, in case there’s no value for the key in cache, at that time of cache lookup.
- Cache Reference: To alleviate repeat heavy weight operations like connection pools, etc., for each data set, it is recommended to initialize such references at partition level. The reference implementation here initializes the cache (a singleton reference per JVM instance) on forEachPartition{…}, when defining the Spark Stream transformation logic. Refer to the cache statistics from a micro-batch outcomes below, for further understanding.
- Type Instantiation: Constructor method lookup and invocation – I shall call this a first-class issue here. If I cannot instantiate a type, what’s the whole need for something like gBoxADTBase implementation. The macro-expansion logic adds a like-wise method on the type’s companion object –
def initialize(...):Try[T].- Note – This would not solve the type-safety concern, where-by some-one could instantiate the object using the compiler generated
def apply(...)signature. This is certainly an opening here to abuse the types. Compiler wouldn’t resolve for a user defined apply(…) signature, instead it will complain about duplicate method error. Wish I could get this solved! - See that return type there, instead of Either[Throwable, T], preferred to use a Try[T], which makes it more visually appealing to describe the verb here. Nothing that’s wrong with Either idiom.
- Note – This would not solve the type-safety concern, where-by some-one could instantiate the object using the compiler generated
- Access to Constructor Argument Names: Another issue in the similar lines is ability to access user defined i.e., canonical attribute names. In Scala 2.11.x, it is not possible to retain such references. There’s compiler debug flag that can be set, but needs developer descipline. To address this, the macro-expansion now adds another static method to the Type’s companion object –
def getCtorArgs():Array[String]. This is used by the gBoxTypeHelper’s getTypeConstructorAndItsArgs[T] method. Instead of returning a tuple of type(ru.MethodMirror, List[ru.Symbol]), it returns(java.lang.reflect.Method, Object, List[(String, ru.Symbol)]), where `ru` is a reference to scala.reflect.runtime.universe!- Hence as a recommendation a suggested practice applied always is to enable cache reference in the run-time.
def helloWorld(Spark Streaming + gBoxADTBase[_])
Okay, that was a bunch of operational stuff. Let us now look at a hello world example. Consider following type composition:
@ItsAGBoxADT(doesValidations = true) case class gBoxSampleADT(name: String, address: String, validated: Boolean = false, validatedBy: String = "")
The parameters validated and validatedBy are audit columns i.e., attributes in the row. These are asserted as part of processing and on-receipt of the in-bound record by the streaming job. Other than demonstrating some data processing task, these do not hold any other technical relevance for the moment.
Note – there’s an open user story that I need to address to allow partial entries in the serialized in-bound data sets. Until such time, assume we send a complete HOCON to the network socket. Here’s one such example:
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy="",validated=false,address="World",name="Hello1"}}}}}}}} Empirical Data Flow
Here is an empirical view of the stream data processing workflow:
For reference I have designed a generic streaming pipeline to take care of Spark orchestration logic. In there, once the streaming context is initialized and a reference to InputDStream is obtained, it invokes the essential data processing logic implementation method – processInputStream(ReceiverInputDStream[Either[Throwable, T]]): Unit.
Following visual describes the technical data flow within the socket streamer:
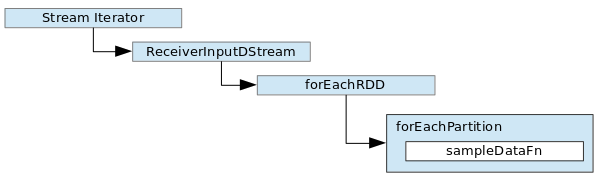
And the generic boiler-plate to setup the streaming pipeline is as follows:
protected def processInputStream(inputDStream: ReceiverInputDStream[Either[Throwable, T]])(implicit cTag: ClassTag[T]): Unit
@inline private def processSocketStreams(
sc: SparkContext,
socket: gBoxCPETLStreamingCfgForSockets,
cTag: ClassTag[T]): Unit = {
//Initialize the streaming context
val streamingContext = new StreamingContext(sc, Duration(socket.batchInterval))
val inputADTDStream: ReceiverInputDStream[Either[Throwable, T]] =
streamingContext.socketStream[Either[Throwable, T]](
hostname = socket.hostName,
port = socket.portNumber,
converter = (inStream: InputStream) => { new gBoxCPETLSocketStreamIterator[T](inStream, cTag.runtimeClass.getCanonicalName) },
storageLevel = socket.storageLevel)
//Set the plan to act on the stream
processInputStream(inputADTDStream)(cTag)
//Start the streaming context
streamingContext.start()
//Await termination
streamingContext.awaitTermination()
} Stream Converter
A stream converter is a function of the socket stream. One can register a custom converter of type Iterator when defining the StreamingContext’s socketStream. See the value assignment to the converter attribute in the preceding code snippet. The converter is passed a reference to the java.io.InputStream. The iterator functions act as a facade and fetch next line from the stream, as orchestrated by Spark’s receiver logic. Each processed next data element is added to the blocks. Blocks are intermediate data stored by Spark and managed by it’s BlockManager. At the turn of each block interval cycle, they are translated to RDD. These RDD are then passed onto the downstream stages per defined transformation logic.
The converter function that we pass in here generates deserialized Types. Instead of suppressing deserialization errors, each deserialization attempt (i.e., use of hoconToType[T]) returns an idiom of type Either[Throwable, T]. This will give downstream an opportunity to track failed cases and apply different treatment to them, like marking such in-bound data as bad and register it so, for other kinds of supervision.
Let’s quickly review how type references are passed onto the deserialization layer. Here’s the class signature of the converter implementation:
private[spark] class gBoxCPETLSocketStreamIterator[O <: gBoxADTBase[O]](inStream: InputStream, adtFQCN: String) extends Iterator[Either[Throwable, O]]
Note the type parameter – O and the Fully-Qualified Class Name of the type that we’d like get. The converter will use this to initialize corresponding TypeTag[O], and pass it as a reference to the deserialization method.
Now to the actual code that actually reads in-bound stream of data and apply deserialization is as follows:
//Method where deserialization is attempted using implicit hoconToType signature
private def fetchNext(): Unit = {
val nextInput: String = streamReader.readLine()
logger.info(s"Received next record from stream $nextInput")
if (nextInput != null) {
nextElement = nextInput.hoconToType[O]()(tTag)
if (nextElement.isLeft) {
logger.error(s"Next element is errored - ${nextElement.left.get.getMessage}", nextElement.left.get)
}
gotNext = true
} else {
logger.error("......Setting end of stream as true")
endOfStream = true
}
} Hello-world Transformation
Okay, that is more about how the stream is orchestrated. Let us now look at the hello-world transformation in our mock pipeline that extends the commons streaming pipe trait.
protected def processInputStream(inputDStream: ReceiverInputDStream[Either[Throwable, gBoxSampleADT]])(implicit cTag: ClassTag[gBoxSampleADT]): Unit = {
inputDStream.foreachRDD { rdd: RDD[Either[Throwable, gBoxSampleADT]] =>
//Initialize accumulators i.e., counters to track good data vs. bad data
rdd.foreachPartition(iter:Iterator[Either[Throwable, gBoxSampleADT]] => {
//Initialize cache
cacheInitializer.initializeCache(){
//Let spark handle failures
case Failure(error) => throw error
case Success(cacheSet:Unit) => {
//Process the stream
while(iter.hasNext){...}//accumulate good and bad records
//Prepare process summary
val summary = s"""In-bound processing status:
Failed2Serialize - ${failed2Serialize.mkString("\n")}
Good Records - ${goodRecords.mkString("\n")}
Bad Records - ${badRecords.mkString("\n")}
Cache Utilization Stats - ${
cacheInitializer.getCacheStats() match {
case Failure(error: Throwable) => s"Error retrieving cache stats - ${error.getMessage()}"
case Success(stats: String) => stats
}
}""".stripMargin
//Print summary to System.out
println(summary)
}
}
}
}
} All this does is, at each micro-batch iteration for each partition iterates through the RDD set, gathers good and bad in-bound data counters and prints the summary to the System.out. Here’s a sample of that:
In-bound processing status:
Failed2Serialize -
Good Records - me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello1"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello2"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello3"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello4"}}}}}}}}
...//suppressed other entries for brevity!
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello25"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello26"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello27"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello28"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello29"}}}}}}}}
me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="1-PartitionID-0",validated =true,address ="World",name ="Hello30"}}}}}}}}
Bad Records -
Cache Utilization Stats - CacheStats{hitCount=29, missCount=1, loadSuccessCount=0, loadFailureCount=0, totalLoadTime=0, evictionCount=0, evictionWeight=0} As you observe, we had one cache miss, when the build-order must be established for the very first in-bound line that the receiver has received. For all subsequent entries, we could just reference the cached value
Some Web-UI Snapshots
Accumulators
In the pipeline setup where we extend the processInputStream method, I have added two counters (accumulators as setup at the driver) – failedDeserializationsCounter and validatedDeserializationsCounter. In case these are utilized in the code as defined by the logic, they show up at the corresponding stage in the compute flow.
AccumulatorNumber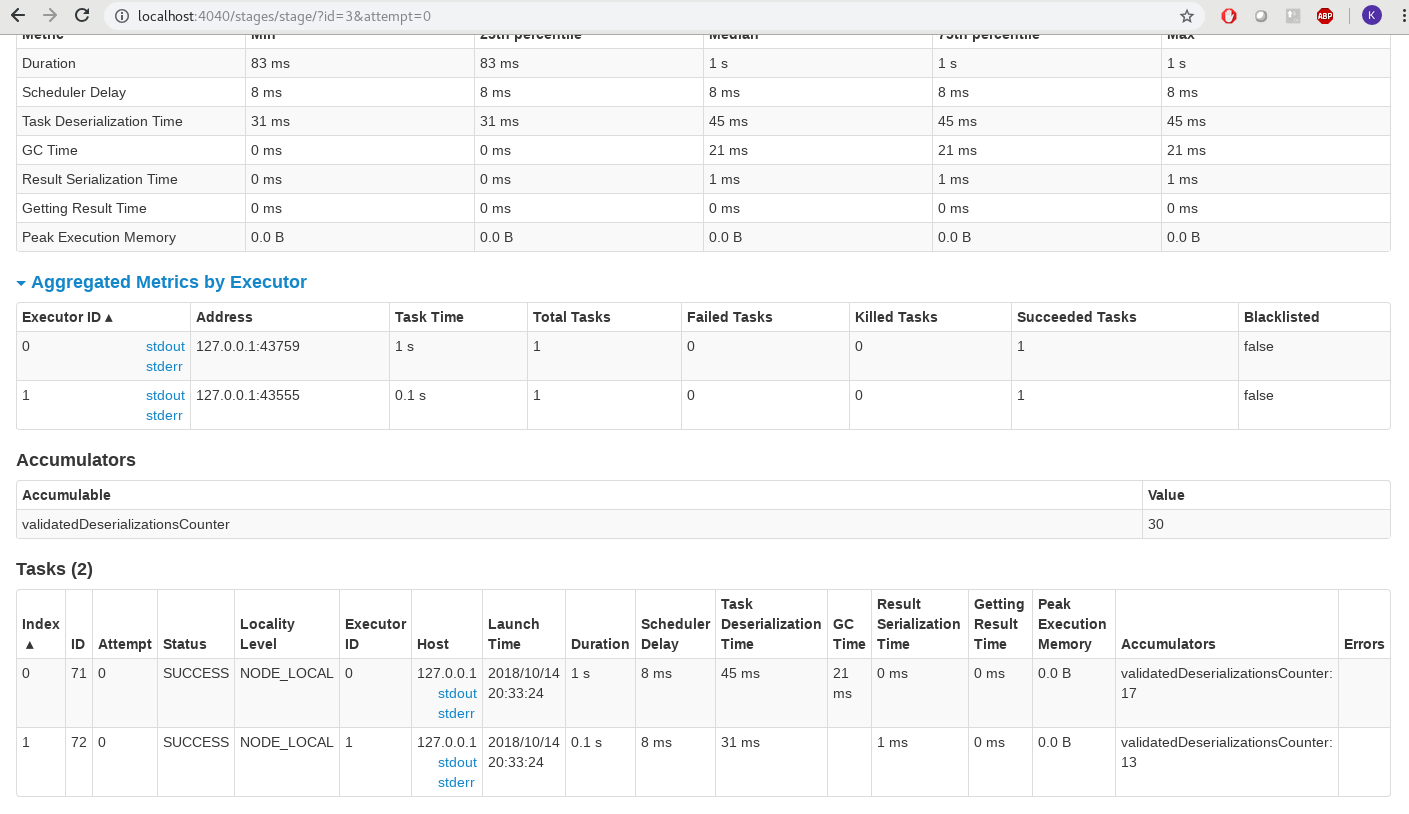
Some Interesting Logs
Job Initialization
Logs where the configured ADT type on the pipe is registered with the KryoRegistrar instance (there’s a internal queue of class names it maintains):
18/10/14 20:29:07 INFO EventLoggingListener:54 Logging events to file:/var/log/applogs/spark/event/app-20181014202907-0001 18/10/14 20:29:07 INFO StandaloneSchedulerBackend:54 SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 18/10/14 20:29:07 DEBUG gBoxCPETLMockScktStrmgPipe$:83 Registered gBoxADTBase types for kryo-registration - [gBoxCPADTKryoRegistrationSpec(class me.ganaakruti.gboxcp.etl.streaming.spark.mock.gBoxSampleADT$,me.ganaakruti.gboxcp.etl.streaming.spark.serde.gBoxADTBaseTypesSerDe@4e08acf9)] 18/10/14 20:29:07 DEBUG gBoxCPETLMockScktStrmgPipe$:84 Initiating processSocketStreams 18/10/14 20:29:08 INFO SparkContext:54 Starting job: start at gBoxCPETLStreamingApp.scala:115
Cache Initialization
Cache is initialized for each partition, and here is the log entry for that:
18/10/14 19:15:00 DEBUG gBoxCPETLMockScktStrmgPipe$:167 Will set cache and iterate through RDD batch for this partition 18/10/14 19:15:00 DEBUG gBoxCPETLMockScktStrmgPipe$:171 Successfully initialized and set cache reference to runtime!
Deserialization
Deserialization log entries spotted from executor that hosts the receiver:
18/10/14 19:14:55 INFO gBoxCPETLSocketStreamIterator:49 Received next record from stream me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy="",validated=false,address="World",name="Hello30"}}}}}}}}
18/10/14 19:14:55 DEBUG gBoxADTBuilder$:177 Arguments to the constructor = [Hello30,World,false,]
18/10/14 19:14:55 DEBUG gBoxADTBuilder$:180 Method constructor to invoke initialize, [class java.lang.Stringclass java.lang.Stringbooleanclass java.lang.String]
18/10/14 19:14:55 DEBUG gBoxADTBuilder$:193 Initialized instance of type TypeTag[me.ganaakruti.gboxcp.etl.streaming.spark.mock.gBoxSampleADT$]
18/10/14 19:14:55 DEBUG gBoxCPETLSocketStreamIterator:87 Returning next element Right(me{ganaakruti{gboxcp{etl{streaming{spark{mock{gBoxSampleADT{validatedBy ="",validated =false,address ="World",name ="Hello30"}}}}}}}})
18/10/14 19:14:55 INFO MemoryStore:54 Block input-0-1539569695000 stored as values in memory (estimated size 6.7 KB, free 413.8 MB)
18/10/14 19:14:55 INFO BlockGenerator:54 Pushed block input-0-1539569695000 Next Steps
Well, this is being paused here without concluding on the Structured Streaming examples. Will soon be adding them here, hopefully with a more mature use case than a simple hello-world.
References
- Compiler Capabilities (Java/Scala):
- Scala:
- Spark: